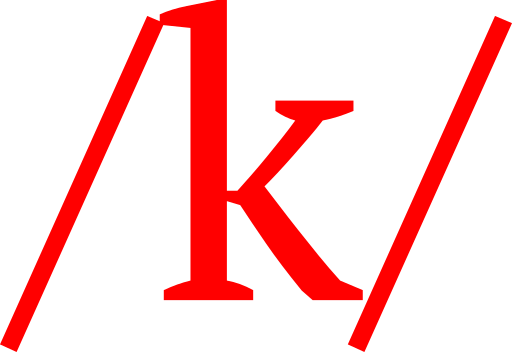

Very recently – as in within 11 days of this article’s publication – an incredible piece of research has been unveiled relating directly to children’s language acquisition.
On the 1st of February of 2024, a research article was published in the Science journal titled Grounded language acquisition through the eyes and ears of a single child by W. K. Vong et al. (linked here https://doi.org/10.1126/science.adi1374). This article details an experiment in which they used machine learning to prove a point I’ve been baselessly arguing every time I’m presented the chance: language learning does not require an innate or uniquely human knowledge of language.
As profound as the previous paragraph may sound, you wouldn’t be alone in wondering what it actually means. Machine learning? Child language acquisition and innatism? How do these relate? And perhaps a more pressing question – what actually is machine learning? Sure, ChatGPT is pretty cool and the term AI or artificial intelligence is thrown around everywhere these days, but why does no one actually explain how it works? And how did the researchers obtain whatever data was used in their experiment for me to be able to make as concrete and brave a statement as the one with which I ended the previous paragraph?
The easy question first: how was data obtained to feed the machine to learn from? By strapping a camera and microphone to the forehead of a baby, of course! Pictured below is Sam, an adorable little baby to whom a camera helmet was attached at various intervals from 6 to 25 months old to get 61 hours of input. This input was entirely unlabelled and unaltered, to ensure that the data fed to the AI model was entirely unaltered from what the baby saw and heard.

Next comes machine learning. What is it? Or at least, what is it in this particular application? Machine learning as a concept is fairly self explanatory, it’s a machine that learns for itself how to perform a function instead of being explicitly coded to perform that function. Think of it as a human who learns to use a tool through actually trying to use it, instead of being explicitly told how to use it by someone else. This particular application of machine learning is referred to by the report as the Child’s View for Contrastive Learning, or CVCL for short (catchy name, I know), and is an example of a neural network.
Neural networks are – as the name suggests – designed to mimic the structure of the brain, with each function being called a ‘neuron’ and these being arranged in ‘layers’. There is always an input and an output layer, but in between there is at least 1 processing layer, referred to as a ‘hidden’ layer or layers (as is shown in the diagram below). An input is provided to the system and it is left to its own devices to provide an output. This output is then compared to an expected output, and the neurons in the hidden layer are given greater or lesser weighting based on their ability to lead to the expected answer, and repeat. It sounds rather complicated (because it is, in fairness), but here is an example to illustrate the process.

Let’s imagine we are making a neural network to answer the question “Is this picture a cat?”. We’ll first give it a picture of a cat. This is seen by the input neurons and they activate the hidden neurons, which then produce a probability of the image being a cat. We then tell it: “This is a cat”, and it will recalibrate itself until it is able to identify reliably that, yes, the image is in fact a cat. Then we feed it a different picture of a cat and repeat until it can reliably identify both cats. Then we feed it a picture of something that is not a cat, and repeat until it learns that it is NOT a cat. And so on and so forth with any number of images until we can feed it a new image it has never seen before and it can identify if it is or isn’t a cat. This experiment was actually done by Google in 2012, and the neural network was able to reliably identify cats, but also produce a cat when asked to do so. Admittedly, it looks not nearly as lifelike as the AI-generated art of today, but – for an image that’s 12 years old – I think it’s rather impressive.

But this (and almost every) example of a neural network relies on human input, a huge flaw in my statement at the beginning of the article, as – if human training is involved – then how can a machine be said to be self-taught in language, in the same way that a young child might be? The use of human training must be eliminated altogether, and that is exactly what was done for the CVCL. A learning model was used called ‘contrastive learning’, in which the audio and video feeds from the camera and microphone are matched up, such that any input that occurs simultaneously is a correct input, and any other input is an incorrect one. This can be illustrated with another example. Say, at 30 seconds into a video, a person says “cat!” as a cat appears. The correct input is matching the audio “cat” with the visual cat. An incorrect input would be using the visuals of a cat from 30 seconds, but the audio from 40 seconds in, when a person says “dog!”, for example. Anything that is synchronous is right, and anything asynchronous is wrong.
Using this model, could a neural network learn to differentiate the “This is a cat” from just the “Cat”, just as a human has to learn to do? The new report would suggest that the answer to this is yes. This question has been debated for decades by philosophers and linguists even just for humans, wondering how a person can differentiate “ball” to mean a round bouncy object as opposed to a cube, or differentiate it from other round objects like a marble or a circle, but philosophy is a whole other can of worms, maybe for another time.
The ability of the trained neural network to identify the correct object was done by presenting it with 4 images and asking it to identify the item that was named, and – assuming CVCL was able to give the correct response over 25% of the time – it would be reasonable to assume it had made at least some progress towards use of language, and it achieved a 62% accuracy rate, much higher than what could be attributed to chance, going directly against the ideas of linguists like Chomsky who posit that language learning is uniquely human and has some component that is innately known, making it impossible for other beings or intelligence (including artificial ones) to grasp it to the same extent as us.
These findings are “among the strongest data I’ve seen showing that such ‘special’ mechanisms are not necessary,” according to Heather Bortfeld, a cognitive scientist at the University of California, Merced. These findings are coincidentally also the strongest data that I, the author, has seen to support going against innatist ideas of language acquisition, so as much as I very much support Chomsky’s political views, I am sorry to have to have to say that – just as with many other professions – artificial intelligence has rendered his linguistic career obsolete.
Leave a Reply